机器学习笔记 - 贝叶斯分类法推导
目录
这篇笔记记录了最近对贝叶斯分类法的学习和理解。
1.概率基本概念回顾
1.1.概率:
事件发生的概率 = $ \dfrac{事件可能发生的个数} {结果的总数} $
1.2.事件的分类:
- 独立事件:每个事件的发生是独立的,不受其他事件的影响,例如:抛硬币,掷骰子。
- 相关事件:当前事件受之前发生事件的影响,例如:抽扑克牌。
- 互斥事件:事件发生只能是其一,不能同时发生,例如:一枚硬币不能同时为正面和反面。
1.3.独立事件的概率:
- 单个独立事件的概率: P(A) = $ \dfrac{事件可能发生的个数} {结果的总数} $
- 事件A和B发生的概率(多个独立事件的概率): P(A B) = P(A) * P(B)
1.4.条件概率:
在相关事件的情况中应用条件概率,用 P(B|A) 表示在事件 A 发生的条件下事件 B 发生的概率。
事件A和B发生的概率: P(A B) = P(A) * P(B|A)
另外一个有用的公式转换: P(B|A) = $ \dfrac{P(A B)} {P(A)} $
在事件 A 发生的情况下 B 发生的概率等于事件 A 和 B 的概率除以事件 A 的概率
例子:冰淇淋
在你的社交群组里,70% 喜欢巧克力冰淇淋,35% 喜欢巧克力和草莓。 在喜欢巧克力的人里,也喜欢草莓的百分比是多少? P(草莓|巧克力) = P(巧克力 与 草莓) / P(巧克力) 0.35 / 0.7 = 50% 在喜欢巧克力的人里,50% 也喜欢草莓
1.4.1. 尝试计算下面的概率
4个人在5个数字中各选一个数字,请问任何两个人选重的概率是多少?

2.贝叶斯定理
$ P(A|B) = \dfrac {P(A)*P(B|A)} {P(B)} $
在 B 发生的情况下发生 A 事件的概率 P(A|B) 可以通过已知 A 发生情况下 B 发生的概率和 A 与 B 的独自发生的概率求出来。
- P(A|B):在 B 发生的情况下 A 发生的概率
- P(A):A 发生的概率
- P(B):B 发生的概率
- P(B|A):在 A 发生的情况下 B 发生的概率
例子1:计算天气有云时下雨的概率:
$ P(雨|云) = \dfrac {P(雨)*P(云|雨)} {P(云)} $
- P(雨):下雨的概率 = 10%
- P(云|雨):下雨时有云的概率 = 50%
- P(云):有云的概率 = 40%
$ P(雨|云) = \dfrac {0.1 * 0.5} {0.4} = 0.125 $
例子2:
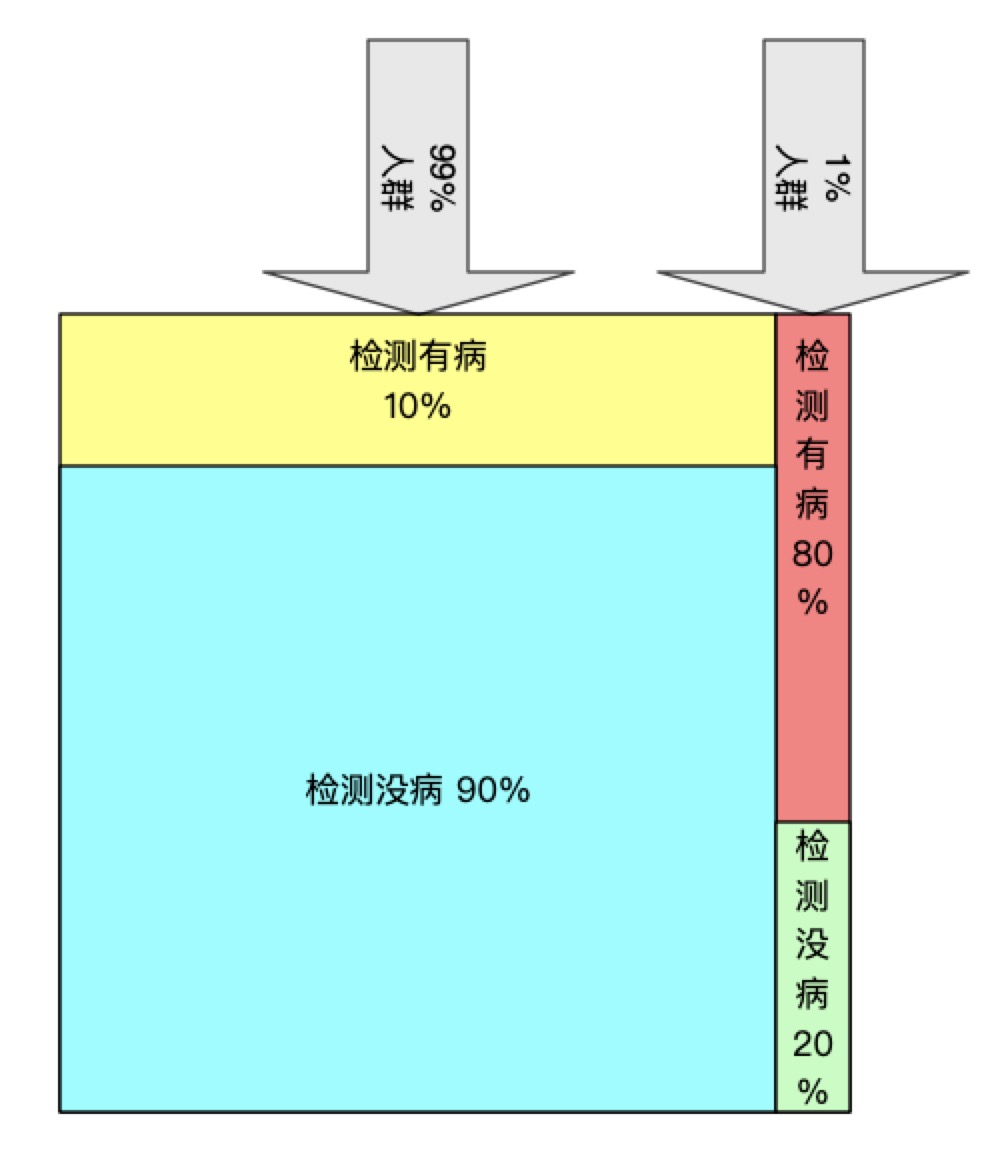
有一种疾病检测手段,但是这种检测手段并不准确
- 在真正有这种疾病的人中有 80% 的人可以被检测出
- 对于没有这种疾病的人有 10% 的概率会被错误检测出
- 以往的统计数据表明人群中有 1% 的人得了这种疾病,99% 的人没有得过
请问,当有一个人被检测出有该疾病时他真正有这种病的概率是多少?
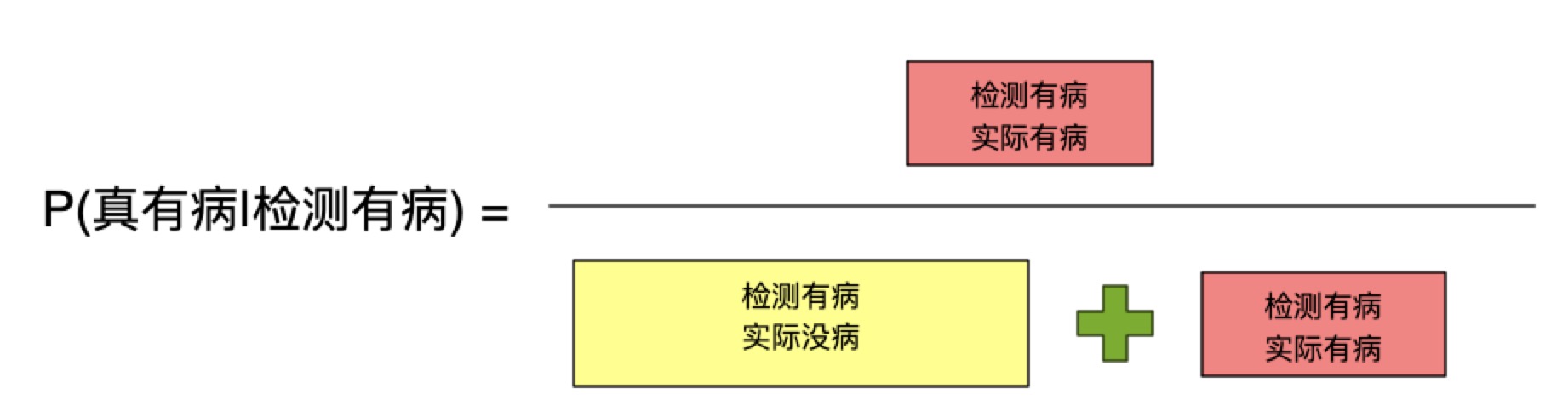
$ P(真有病|检测有病) = \dfrac {P(真有病) * P(检测有病|真有病)} {P(检测有病)} $
| 真实情况 \ 检测结果 | 检测有病 | 检测没病 | 得病统计 |
|---|---|---|---|
| 真有病 | 80% | 20% | 1% |
| 真没病 | 10% | 90% | 99% |
- P(真有病):1%
- P(检测有病|真有病):80%
- P(检测有病):P(没有病的人被检测出有病的概率) + P(真有病的人被检测出有病的概率)
- P(没有病的人被检测出有病的概率) = P(真没病) * P(检测有病|真没病) = 99% * 10% = 0.099
- P(真有病的人被检测出有病的概率) = P(真有病) * P(检测有病|真有病) = 1% * 80% = 0.008
$ P(真有病|检测有病) = \dfrac {1\% * 80\%} { 99\% * 10\% + 1\% * 80\%} = 7.48\% $
示意图:
计算方法:
那么怎么评估这个方法是否有效呢?可以使用准确度(Precision)和召回(Recall)两个指标来评估。
$ Precision = \dfrac {TP} {TP + FP} = \dfrac {P(真有病) * P(检测有病|真有病)} {P(检测有病)} = \dfrac {1\% * 80\%} {1\% * 80\% + 99\% * 10\%} = 7.48\%$
$ Recall = \dfrac {TP} {TP + FN} = \dfrac {P(真有病) * P(检测有病|真有病)} {P(真有病)} = \dfrac {1\% * 80\%} {1%} = 80\% $
3.贝叶斯定理在机器学习中的应用 - 文本分类
任务目标:通过利用一批分好类(2类:正常/非正常)的文本信息,训练一个模型来识别一段给定文字,判断是不是正常言论。
$ P(类别|数据) = \dfrac {P(类别) * P(数据|类别)} {P(数据)} $
- 当 P(正常|数据) > P(不正常|数据) 时认为文本为“正常”
- 当 P(正常|数据) < P(不正常|数据) 时认为文本为“不正常”
算法推导:
进一步把问题转换成下面的表达方式:
$ P(class|words) = \dfrac {P(words|class) * P(class)} {P(words)} $
- class:代表类别
- words:代表一句话,它是由一组单词构成的,记做:w0, w1, w2, …, wn
$ P(class|w0, w0, w1, w2, …, wn) = \dfrac {P(w0, w1, w2, …, wn|class) * P(class)} {P(w0, w1, w2, …, wn)} $
由于 P(w0, w1, w2, …, wn|class) 非常难于计算因此通过条件独立性假设把这个概率进行简化计算,最终转换成计算 P(w0|class)P(w1|class)P(w2|class)…P(wn|class)。
$ P(class|w0, w0, w1, w2, …, wn) = \dfrac {P(w0|class)*P(w1|class)*P(w2|class)…P(wn|class) * P(class)} {P(w0, w1, w2, …, wn)} $
训练方法就转换成根据已提供的数据计算下列概率值得过程:
- 每个类别中出现某个单词的概率 P(w0|class), P(w1|class), P(w2|class)…P(wn|class)
- 训练数据中某个类别的概率 P(class)
比较 P(class1|w0, w0, w1, w2, …, wn) P(class2|w0, w0, w1, w2, …, wn) 可以简化成比较
$ P(w0|class1)*P(w1|class1)*P(w2|class1)…P(wn|class1) * P(class1) $
$ P(w0|class2)*P(w1|class2)*P(w2|class2)…P(wn|class2) * P(class2) $
注意:实际计算中很少直接使用这样的乘法进行计算,主要原因是:
- 乘法运算计算量相对加法来说是复杂很多的
- 由于每一项 P(wn|class1) 值很小或者为0(有时为了避免所有项为0会把每一项给一个初始化很小的数字),因此容易导致计算结果直接为0或者由于太小造成下溢出
所以,在实际情况下多使用 log 运算,根据 log 的性质可以进一步简化成比较:
$ log(P(w0|class1)*P(w1|class1)*P(w2|class1)…P(wn|class1) * P(class1)) = log(P(w0|class1) + log(P(w1|class1) + log(P(w2|class1) + … + log(P(wn|class1) + log(class1)$
$ log(P(w0|class2)*P(w1|class2)*P(w2|class2)…P(wn|class2) * P(class2)) = log(P(w0|class2) + log(P(w1|class2) + log(P(w2|class2) + … + log(P(wn|class2) + log(class2)$
另外使用 log 进行计算还有额外的好处:
- 首先是直接将乘法运算转换成了加法,计算速度得到提升
- 每一项 log(P(wn|class) 都可以在训练阶段固化,操作中可以直接用查表法解决进一步减少运算量
最后,引用一下来自《机器学习实战》的例子:
from numpy import *
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec
def createVocabList(dataSet):
vocabSet = set([]) #create empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords); p1Num = ones(numWords) #change to ones(),备注:初始化成1避免该项为0的情况发生
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()
p0Vect = log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
第一步:加载已分类数据,并创建词典
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
print('All posts:')
print('-'*80)
print(listOPosts)
print('\n')
print('Vocabulary:')
print('-'*80)
print(myVocabList)
All posts:
--------------------------------------------------------------------------------
[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
Vocabulary:
--------------------------------------------------------------------------------
['to', 'mr', 'quit', 'take', 'my', 'dalmation', 'is', 'has', 'flea', 'stop', 'worthless', 'him', 'problems', 'cute', 'maybe', 'I', 'so', 'not', 'buying', 'help', 'how', 'park', 'food', 'garbage', 'steak', 'please', 'dog', 'ate', 'licks', 'posting', 'love', 'stupid']
第二步:将词典数据转换成可计算的向量
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
第三步:训练模型
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
最后:测试模型
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
['love', 'my', 'dalmation'] classified as: 0
['stupid', 'garbage'] classified as: 1
