机器学习 - 决策树
目录
机器学习-决策树
1.什么是问题树?
请思考以下场景
1.1.玩过猜字游戏吗?

1.2.如何通过几个问题区分“猫狗鸡鸭”?

1.2.1.他们的特征是什么?
| 物种 | 腿的数量 | 有没有脚蹼 | 喙的形状 | 会不会游泳 |
|---|---|---|---|---|
| 猫 | 4 | 没有 | 没有 | 不会 |
| 狗 | 4 | 没有 | 没有 | 会 |
| 鸡 | 2 | 没有 | 尖 | 不会 |
| 鸭 | 2 | 有 | 扁 | 会 |
数据的表示方法:
- 类别:猫、狗、鸡、鸭
- 特征:腿的数量、有没有脚蹼、喙的形状,会不会游泳
1.2.2.以下是一种区分方法
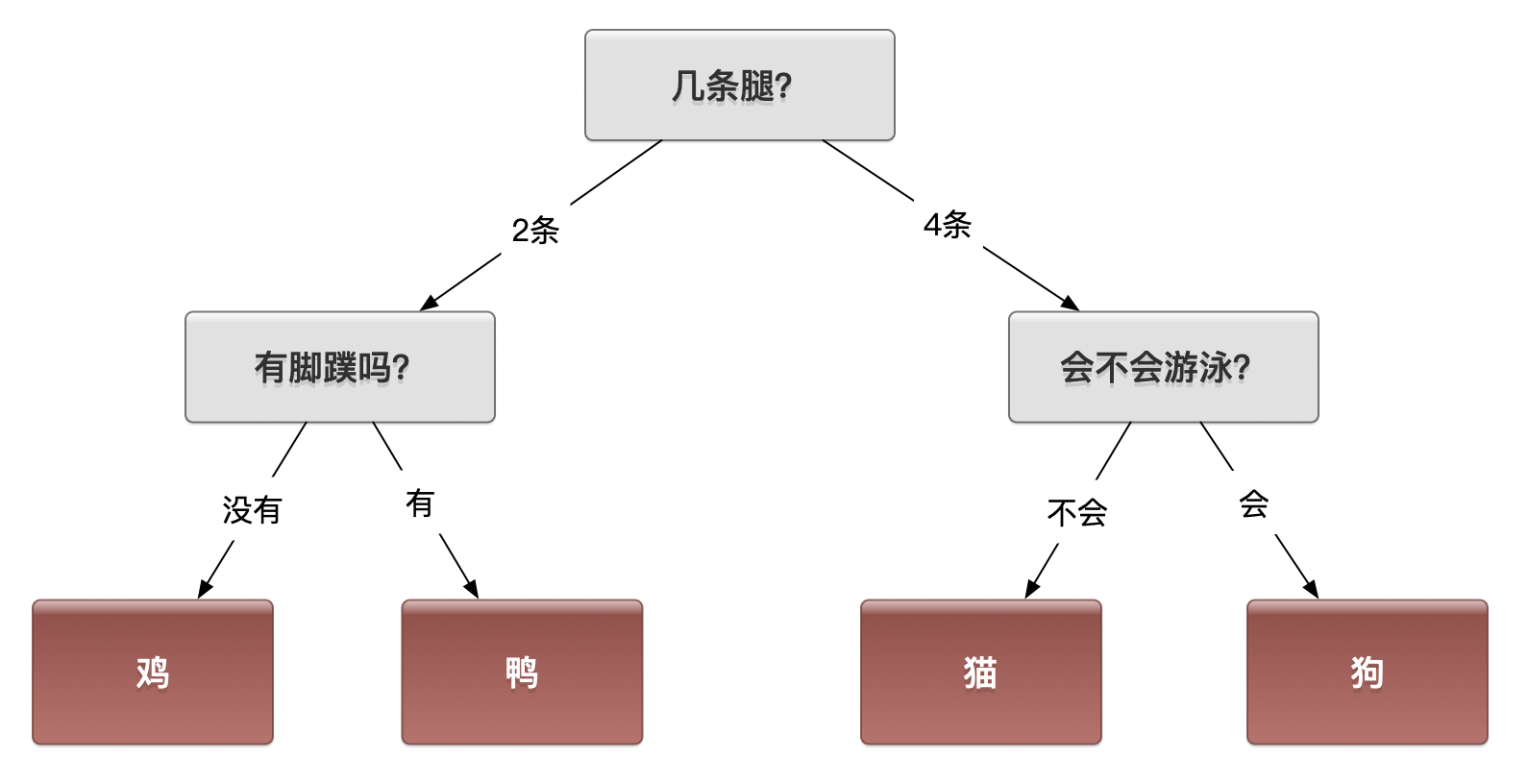
思考1:以上是不是唯一的方法?
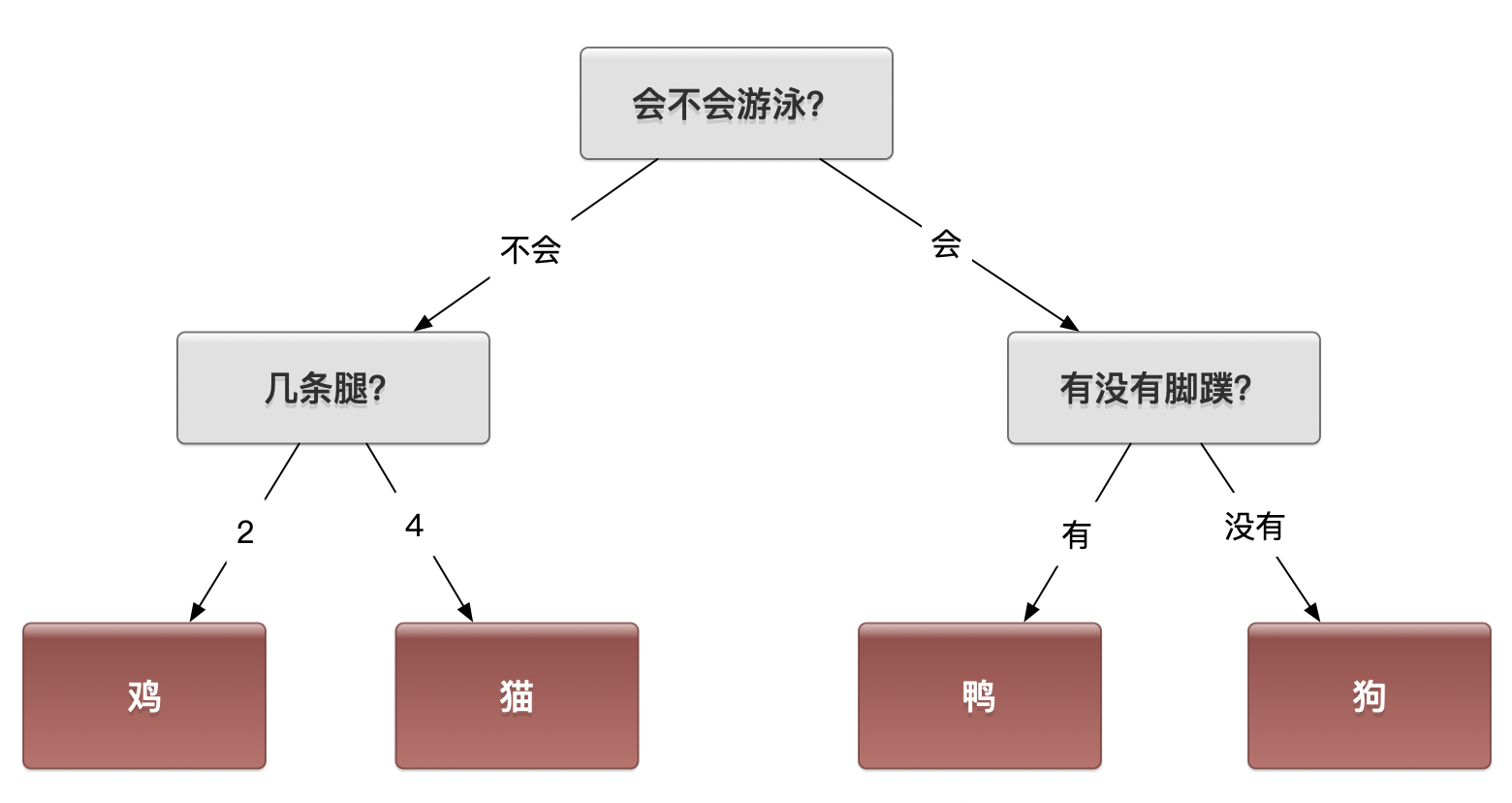
思考2:哪种判定方式更好?
思考3:如何更有效的区分?
- 如果某个特征区分问题更有效?
- 怎么判断问题更有效?
2.为什么需要决策树
此刻你可能会想到:
1. 寻找关键性问题!
2. 什么是关键性问题?
3. 怎么寻找关键性问题?
2.1.理论依据是什么?
“香农”提出信息论,其中对信息的度量成为香农熵,简称“熵(Entropy)”
在分类问题中,假设存在类别集合为 $ (X_1, X_2, … X_n) $ ,将类别 $ X_i $ 的信息定义为:
$ l(X_i) = -log(P(X_i))$ , 其中 $ P(X_i)$为 $X_i $的概率
熵:信息的数学期望值: $ H= -\sum_{i=1}^n P(X_i) log(P(X_i))$
思考4:怎么理解熵?
- 信息量越大,熵越小
- 信息量越小,熵越大
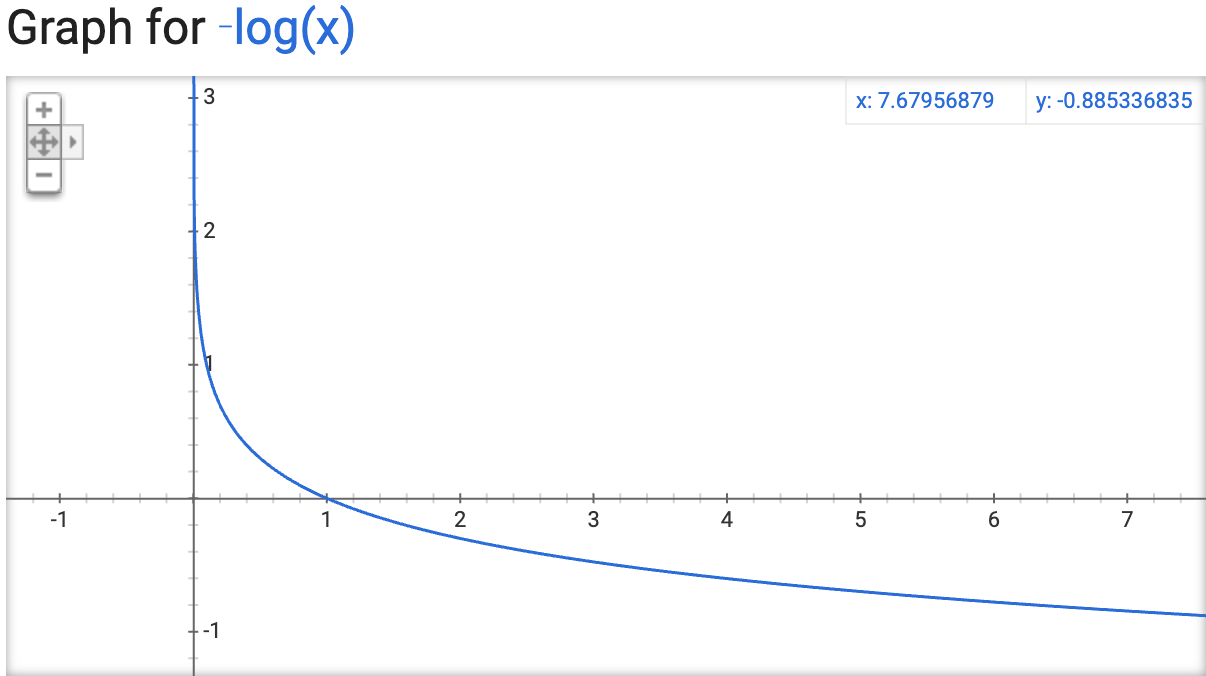
思考5:为什么使用对数表示信息?
概率 vs 信息
- 概率越大,信息量越小
- 概率越小,信息量越大
- 多个事件同时发生的概率是多个事件发生概率相乘,总信息量是多个事件信息量相加
练习1:给定以下数据集,写出熵的计算方法
$$ H= -\sum_{i=1}^n P(X_i) log(P(X_i)) $$
from math import log
def create_dataset():
features = ['legs', 'flippers', 'beak', 'swim']
dataset = [
[4, 0, 'No', 'No', 'cat'],
[4, 0, 'No', 'No', 'cat'],
[4, 0, 'No', 'No', 'cat'],
[4, 0, 'No', 'Yes', 'dog'],
[4, 0, 'No', 'Yes', 'dog'],
[2, 0, 'Sharp', 'No', 'chicken'],
[2, 0, 'Sharp', 'No', 'chicken'],
[2, 1, 'Flat', 'No', 'duck']
]
return dataset, features
def calc_entropy(dataset):
count = len(dataset)
class_counter = {}
for vector in dataset:
cls = vector[-1]
class_counter[cls] = class_counter.get(cls, 0) + 1
entropy = 0.0
for key in class_counter.keys():
prob = float(class_counter[key])/count
entropy -= prob * log(prob)
return entropy
dataset, features = create_dataset()
entropy = calc_entropy(dataset)
print('Entropy: {}'.format(entropy))
Entropy: 1.3208883431493221
3.怎么构建决策树
核心问题:如何通过划分数据集计算信息量的提升来找到最有效的数据特征
练习2:重新划分数据集,将符合指定特征值的数据提取出来组合新的数据集合
def split_dataset(dataset, feature, value):
new_dataset = []
for data in dataset:
if data[feature] == value:
new_data = data[:feature]
new_data.extend(data[feature+1:])
new_dataset.append(new_data)
return new_dataset
小实验1:以下将有脚蹼和没有脚蹼的数据集划分出来
feature = features.index('flippers')
with_flipper_dataset = split_dataset(dataset, feature, 1)
print('Dataset with flippers:')
print(with_flipper_dataset)
print('Dataset without flippers:')
with_flipper_dataset = split_dataset(dataset, feature, 0)
print(with_flipper_dataset)
Dataset with flippers:
[[2, 'Flat', 'No', 'duck']]
Dataset without flippers:
[[4, 'No', 'No', 'cat'], [4, 'No', 'No', 'cat'], [4, 'No', 'No', 'cat'], [4, 'No', 'Yes', 'dog'], [4, 'No', 'Yes', 'dog'], [2, 'Sharp', 'No', 'chicken'], [2, 'Sharp', 'No', 'chicken']]
思考6:怎么表示最好的特征?
- 信息增益:通过观察信息熵的变化求得
def select_best_feature(dataset, features):
feature_count = len(dataset[0])-1
current_entropy = calc_entropy(dataset)
feature_selected = None
best_entropy_gain = 0
dataset_size = len(dataset)
sub_datasets = {}
sub_features = []
for i in range(feature_count):
feature_values = set([vector[i] for vector in dataset])
subset_entropy = 0.0
print(' Calculating entropy by splitting dataset with feature[{0}]'.format(features[i]))
subsets = {}
for value in feature_values:
print(' Splitting dataset with feature[{0}]=={1}'.format(features[i], value))
subset = split_dataset(dataset, i, value)
subsets[value] = subset
prob = (len(subset)*1.0)/dataset_size
subset_entropy += prob * calc_entropy(subset)
print(' Subset:', subset)
print(' Entropy:', subset_entropy)
entropy_gain = current_entropy-subset_entropy
print(' Entropy gain: {}'.format(entropy_gain))
if best_entropy_gain < entropy_gain:
best_entropy_gain = entropy_gain
feature_selected = i
sub_datasets = subsets
sub_features = features[:feature_selected]
sub_features.extend(features[feature_selected+1:])
return feature_selected, sub_datasets, sub_features
小实验2:请在数据全集上运行计算出最优数据特征
best_feature, sub_datasets, sub_features = select_best_feature(dataset, features)
print('Best feature: {}, name: {}'.format(best_feature, features[best_feature]))
for feature_value in sub_datasets.keys():
print('Sub dataset with feature[{}]=={}'.format(features[best_feature], feature_value))
print(sub_datasets[feature_value])
print('Sub features: ', sub_features)
Calculating entropy by splitting dataset with feature[legs]
Splitting dataset with feature[legs]==2
Subset: [[0, 'Sharp', 'No', 'chicken'], [0, 'Sharp', 'No', 'chicken'], [1, 'Flat', 'No', 'duck']]
Entropy: 0.2386928131105548
Splitting dataset with feature[legs]==4
Subset: [[0, 'No', 'No', 'cat'], [0, 'No', 'No', 'cat'], [0, 'No', 'No', 'cat'], [0, 'No', 'Yes', 'dog'], [0, 'No', 'Yes', 'dog']]
Entropy: 0.6593251049913401
Entropy gain: 0.661563238157982
Calculating entropy by splitting dataset with feature[flippers]
Splitting dataset with feature[flippers]==0
Subset: [[4, 'No', 'No', 'cat'], [4, 'No', 'No', 'cat'], [4, 'No', 'No', 'cat'], [4, 'No', 'Yes', 'dog'], [4, 'No', 'Yes', 'dog'], [2, 'Sharp', 'No', 'chicken'], [2, 'Sharp', 'No', 'chicken']]
Entropy: 0.9441181818928854
Splitting dataset with feature[flippers]==1
Subset: [[2, 'Flat', 'No', 'duck']]
Entropy: 0.9441181818928854
Entropy gain: 0.3767701612564367
Calculating entropy by splitting dataset with feature[beak]
Splitting dataset with feature[beak]==No
Subset: [[4, 0, 'No', 'cat'], [4, 0, 'No', 'cat'], [4, 0, 'No', 'cat'], [4, 0, 'Yes', 'dog'], [4, 0, 'Yes', 'dog']]
Entropy: 0.4206322918807853
Splitting dataset with feature[beak]==Flat
Subset: [[2, 1, 'No', 'duck']]
Entropy: 0.4206322918807853
Splitting dataset with feature[beak]==Sharp
Subset: [[2, 0, 'No', 'chicken'], [2, 0, 'No', 'chicken']]
Entropy: 0.4206322918807853
Entropy gain: 0.9002560512685368
Calculating entropy by splitting dataset with feature[swim]
Splitting dataset with feature[swim]==No
Subset: [[4, 0, 'No', 'cat'], [4, 0, 'No', 'cat'], [4, 0, 'No', 'cat'], [2, 0, 'Sharp', 'chicken'], [2, 0, 'Sharp', 'chicken'], [2, 1, 'Flat', 'duck']]
Entropy: 0.7585531985305136
Splitting dataset with feature[swim]==Yes
Subset: [[4, 0, 'No', 'dog'], [4, 0, 'No', 'dog']]
Entropy: 0.7585531985305136
Entropy gain: 0.5623351446188085
Best feature: 2, name: beak
Sub dataset with feature[beak]==No
[[4, 0, 'No', 'cat'], [4, 0, 'No', 'cat'], [4, 0, 'No', 'cat'], [4, 0, 'Yes', 'dog'], [4, 0, 'Yes', 'dog']]
Sub features: ['legs', 'flippers', 'swim']
Sub dataset with feature[beak]==Flat
[[2, 1, 'No', 'duck']]
Sub features: ['legs', 'flippers', 'swim']
Sub dataset with feature[beak]==Sharp
[[2, 0, 'No', 'chicken'], [2, 0, 'No', 'chicken']]
Sub features: ['legs', 'flippers', 'swim']
思考7:如果改动数据集会出现什么情况?
决策树算法
算法描述:
- 当前数据集是否是确定的某个类型的数据,如果是则不用再对该数据集进行分类
- 在当前数据集上选择最好的特征,通过使用这个特征区分的子数据集拥有最好的信息
- 对各子数据集重复进行上述计算
伪代码:
Function CreateTree
IF 数据集不用再分割 THEN return 该数据集类别
ELSE
寻找待分类数据的最好特征
划分子数据集
创建分支节点
for 每个划分的子数据集
branchPoint = CreateTree
return 分支节点
大家动手实现上面的算法,输出一棵树
4.其他思考
思考8:数据集有什么样的影响?
思考9:数据特征有什么样的影响?
例如:
# 'meow':0, 'wong':1, 'googooda':2, 'ga':3
def create_dataset():
features = ['legs', 'flippers', 'voice']
dataset = [
[4, 0, 0, 'cat'],
[4, 0, 0, 'cat'],
[4, 0, 0, 'cat'],
[4, 0, 1, 'dog'],
[4, 0, 1, 'dog'],
[2, 0, 2, 'chicken'],
[2, 0, 2, 'chicken'],
[2, 1, 3, 'duck']
]
return dataset, features
| 物种 | 腿的数量 | 有没有脚蹼 | 叫声 |
|---|---|---|---|
| 猫 | 4 | 没有 | 喵喵 |
| 狗 | 4 | 没有 | 旺旺 |
| 鸡 | 2 | 没有 | 咯咯哒 |
| 鸭 | 2 | 有 | 嘎嘎 |
一种区分方法
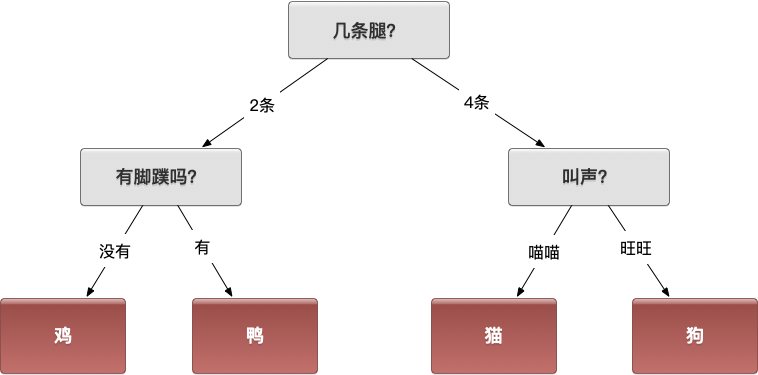
思考10:有没有其他方法?
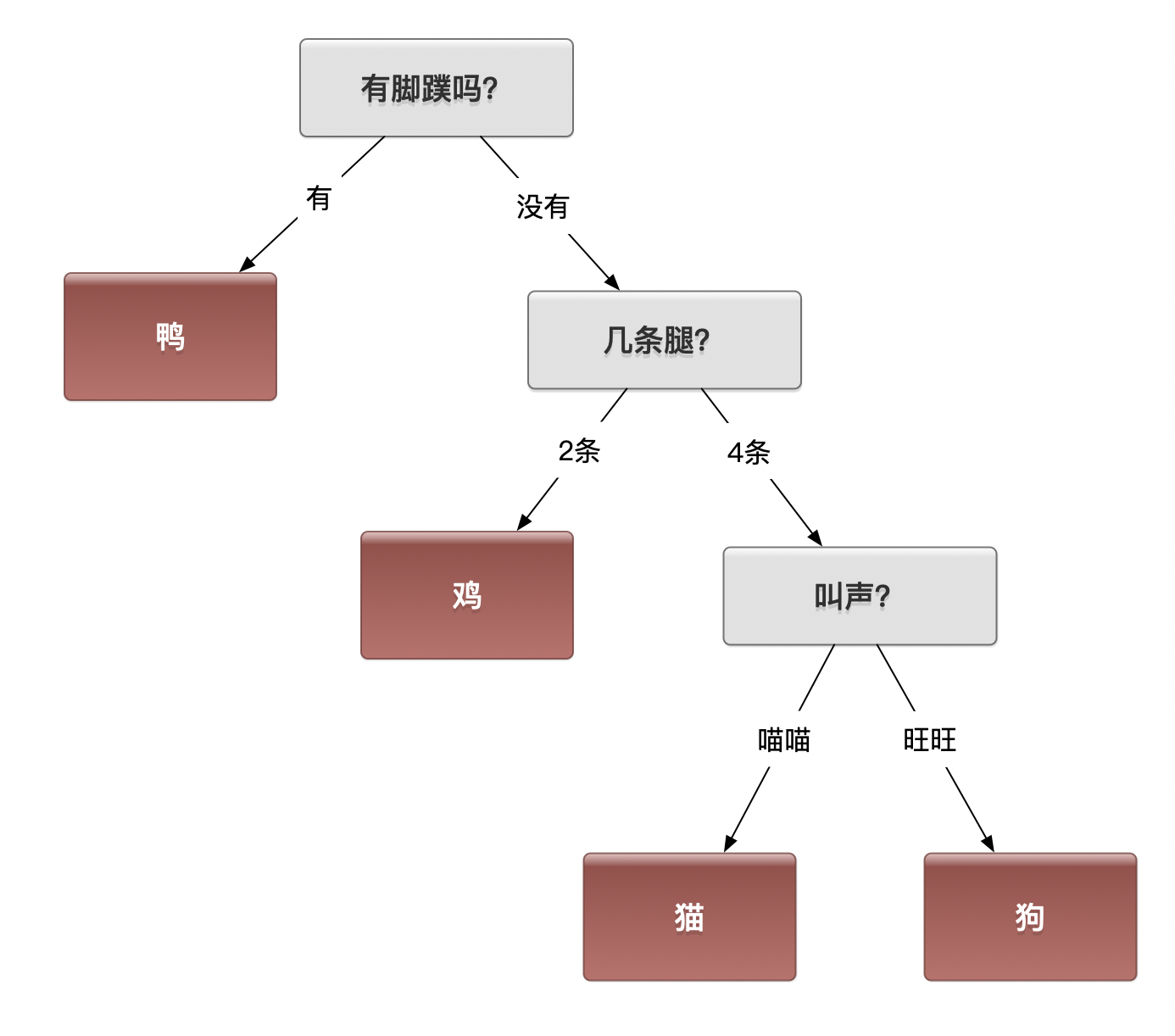
思考11:如果使用前面的算法会得出什么样的结果呢?
