Spark开发
使用scala进行开发
Step1: 安装sbt
$ curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintray-sbt-rpm.repo
$ sudo yum install sbt
配置源:
# cat ~/.sbt/repositories
[repositories]
# 本地源
local
# 阿里源
aliyun: http://maven.aliyun.com/nexus/content/groups/public/
typesafe: http://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
sonatype-oss-releases
maven-central
sonatype-oss-snapshots
Step2: 创建项目
可以使用Giter8模版创建项目。
$ sbt new imarios/frameless.g8
spark相关的几个模版:
- holdenk/sparkProjectTemplate.g8 (Template for Scala Apache Spark project).
- imarios/frameless.g8 (A simple frameless template to start with more expressive types for Spark)
- nttdata-oss/basic-spark-project.g8 (Spark basic project.)
- spark-jobserver/spark-jobserver.g8 (Template for Spark Jobserver)
Step3: 编写代码
创建出的项目目录中包含一下主要条目:
$ ls
build.sbt project src target
编写的代码放在 ‘src/main/scala/’ 目录中:
$ ls src/main/scala/
SimpleApp.scala
$ cat src/main/scala/SimpleApp.scala
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]) {
val logFile = "people.txt" // Should be some file on your system
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
}
Step4: 编译打包
程序开发好之后首先需要编译打包:
$ sbt package
[info] Loading project definition from /home/spark/scala/frameless/project
[info] Updating {file:/home/spark/scala/frameless/project/}frameless-build...
[info] Resolving org.fusesource.jansi#jansi;1.4 ...
[info] Done updating.
[info] Set current project to frameless (in build file:/home/spark/scala/frameless/)
[info] Updating {file:/home/spark/scala/frameless/}root...
[info] Resolving org.sonatype.oss#oss-parent;9 ...
[info] downloading https://repo1.maven.org/maven2/org/scala-lang/scala-library/2.11.11/scala-library-2.11.11.jar ...
[info] [SUCCESSFUL ] org.scala-lang#scala-library;2.11.11!scala-library.jar (94788ms)
...
[info] downloading https://repo1.maven.org/maven2/jline/jline/2.14.3/jline-2.14.3.jar ...
[info] [SUCCESSFUL ] jline#jline;2.14.3!jline.jar (4836ms)
[info] Done updating.
[info] Compiling 1 Scala source to /home/spark/scala/frameless/target/scala-2.11/classes...
[info] 'compiler-interface' not yet compiled for Scala 2.11.11. Compiling...
[info] Compilation completed in 24.981 s
[info] Packaging /home/spark/scala/frameless/target/scala-2.11/frameless_2.11-0.1.jar ...
[info] Done packaging.
[success] Total time: 2795 s, completed Jan 16, 2018 3:03:12 PM
编译打包成功后的文件输出在 ‘target/scala-2.11/’ 目录中:
/home/spark/scala/frameless/target/scala-2.11/frameless_2.11-0.1.jar
Step5: 部署运行
# su - spark
$ export SPARK_MAJOR_VERSION=2
$ spark-submit --class SimpleApp --master yarn-client --num-executors 1 --driver-memory 512m --executor-memory 512m --executor-cores 1 target/scala-2.11/frameless_2.11-0.1.jar
SPARK_MAJOR_VERSION is set to 2, using Spark2
Warning: Master yarn-client is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
18/01/17 15:20:18 INFO SparkContext: Running Spark version 2.2.0.2.6.3.0-235
18/01/17 15:20:19 INFO SparkContext: Submitted application: Simple Application
18/01/17 15:20:19 INFO SecurityManager: Changing view acls to: spark
18/01/17 15:20:19 INFO SecurityManager: Changing modify acls to: spark
18/01/17 15:20:19 INFO SecurityManager: Changing view acls groups to:
18/01/17 15:20:19 INFO SecurityManager: Changing modify acls groups to:
18/01/17 15:20:19 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); groups with view
permissions: Set(); users with modify permissions: Set(spark); groups with modify permissions: Set()
18/01/17 15:20:20 INFO Utils: Successfully started service 'sparkDriver' on port 43573.
...
18/01/17 15:21:30 INFO YarnScheduler: Adding task set 3.0 with 1 tasks
18/01/17 15:21:30 INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID 3, bdtest-002, executor 1, partition 0, NODE_LOCAL, 4737 bytes)
18/01/17 15:21:30 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on bdtest-002:44065 (size: 3.7 KB, free: 93.2 MB)
18/01/17 15:21:30 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to 192.168.1.4:44312
18/01/17 15:21:30 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 1 is 141 bytes
18/01/17 15:21:30 INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID 3) in 96 ms on bdtest-002 (executor 1) (1/1)
18/01/17 15:21:30 INFO YarnScheduler: Removed TaskSet 3.0, whose tasks have all completed, from pool
18/01/17 15:21:30 INFO DAGScheduler: ResultStage 3 (count at SimpleApp.scala:10) finished in 0.096 s
18/01/17 15:21:30 INFO DAGScheduler: Job 1 finished: count at SimpleApp.scala:10, took 0.289165 s
Lines with a: 1, Lines with b: 0
18/01/17 15:21:30 INFO AbstractConnector: Stopped Spark@17b03218{HTTP/1.1,[http/1.1]}{0.0.0.0:4042}
18/01/17 15:21:30 INFO SparkUI: Stopped Spark web UI at http://192.168.1.5:4042
18/01/17 15:21:30 INFO YarnClientSchedulerBackend: Interrupting monitor thread
18/01/17 15:21:30 INFO YarnClientSchedulerBackend: Shutting down all executors
18/01/17 15:21:30 INFO YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
18/01/17 15:21:30 INFO SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,
services=List(),
started=false)
18/01/17 15:21:30 INFO YarnClientSchedulerBackend: Stopped
18/01/17 15:21:30 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
18/01/17 15:21:31 INFO MemoryStore: MemoryStore cleared
18/01/17 15:21:31 INFO BlockManager: BlockManager stopped
18/01/17 15:21:31 INFO BlockManagerMaster: BlockManagerMaster stopped
18/01/17 15:21:31 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
18/01/17 15:21:31 INFO SparkContext: Successfully stopped SparkContext
18/01/17 15:21:31 INFO ShutdownHookManager: Shutdown hook called
18/01/17 15:21:31 INFO ShutdownHookManager: Deleting directory /tmp/spark-730219ef-2995-4225-8743-5769fa6269db
- –master: 指定spark driver的运行模式。
- yarn-cluster: spark driver运行在yarn的application master进程中。如果应用只是进行计算可以使用这种方式运行,如果需要跟前台进行交互则可以考虑yarn-client模式。
- yarn-client: spark driver运行在client进程中,此时application master只负责向yarn申请资源。
使用python进行开发
使用HDP环境提交任务
创建python文件pi.py
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("PythonPi")\.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(any):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
运行pi.py,这里指定使用yarn的cluster模式
SPARK_MAJOR_VERSION=2 spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --deploy pi.py 10
在HDP环境运行jupyter server
使用yarn的cluster模式运行,在运行期间会始终在yarn中占用资源,如果需要长期运行,使用--master local比较好
XDG_RUNTIME_DIR="" SPARK_MAJOR_VERSION=2 PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS='notebook --no-browser --port 8888 --ip 121.43.171.231' pyspark --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m
为jupyter server设置密码等操作参考jupyter文档
运行后访问服务器8888端口即可访问jupyter服务
非HDP环境开发
确保本机有一份spark二进制文件,比如spark-2.2.1-bin-hadoop2.7
安装pyspark
pip install pyspark
设置SPARK_HOME(可选)
export SPARK_HOME=/home/xxx/spark-2.2.1-bin-hadoop2.7
通过代码提交任务
import os
from pyspark import SparkConf, SparkContext
# if `SPARK_HOME` is undefined yet
if 'SPARK_HOME' not in os.environ:
os.environ['SPARK_HOME'] = '/home/xxx/spark-2.2.1-bin-hadoop2.7'
conf = SparkConf().setAppName('Demo').setMaster('yarn').set('spark.yarn.deploy.mode', 'cluster')
sc = SparkContext(conf=conf)
# Do something with sc...
或者使用SparkSession API
from spark.sql import SparkSession
spark = (SparkSession.builder
.master("yarn")
.appName("Demo")
.config("spark.yarn.deploy.mode", "cluster")
.getOrCreate())
# Do something with spark...
oozie自动化
TODO
Development
Spark 2.0之前的开发接口主要是RDD(Resilient Distributed Dataset),从2.0之后原有RDD接口仍然支持,但RDD被Dataset取代,如果使用Dataset编程的话需要使用Spark SQL。
API
http://spark.apache.org/docs/1.3.1/api/scala/index.html
SparkSession vs SparkContext
Spark 2.0之前有3个主要的连接对象:
- SparkContext: 建立与Spark执行环境相关的连接,用于创建RDD
- SqlContext:利用SparkContext背后的SparkSQL建立连接
- HiveContext:创建访问hive的接口
从Spark 2.0开始,Datasets/Dataframes成为主要的数据访问接口,SparkSession(org.apache.spark.sql.SparkSession)成为主要的访问Spark执行环境的接口。
SparkConf
Spark 2.0之前需要先创建SparkConf,在创建SparkContext。
//set up the spark configuration and create contexts
val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local")
// your handle to SparkContext to access other context like SQLContext
val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
Spark 2.0之后可以不用显示的创建SparkConf对象就可以创建SparkSession对象。
// Create a SparkSession. No need to create SparkContext
// You automatically get it as part of the SparkSession
val warehouseLocation = "file:${system:user.dir}/spark-warehouse"
val spark = SparkSession
.builder()
.appName("SparkSessionZipsExample")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
在SparkSession创建完后,Spark的运行时配置属性还可以通过SparkSession.conf()被修改:
//set new runtime options
spark.conf.set("spark.sql.shuffle.partitions", 6)
spark.conf.set("spark.executor.memory", "2g")
//get all settings
val configMap:Map[String, String] = spark.conf.getAll()
SparkSQL
2.0之前需要通过创建SqlContext来使用SparkSQL。
val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
2.0后通过SparkSession可以很方便的访问SparkSession.sql()来使用SparkSQL。
// Now create an SQL table and issue SQL queries against it without
// using the sqlContext but through the SparkSession object.
// Creates a temporary view of the DataFrame
zipsDF.createOrReplaceTempView("zips_table")
zipsDF.cache()
val resultsDF = spark.sql("SELECT city, pop, state, zip FROM zips_table")
resultsDF.show(10)
访问Catalog Metadata
SparkSession暴露了访问metastore的接口SparkSession.catalog,这个接口可以用来访问catalog metadata信息,比如(Hcatalog)
//fetch metadata data from the catalog
spark.catalog.listDatabases.show(false)
spark.catalog.listTables.show(false)
scala> spark.catalog.listDatabases.show(false)
+-------+---------------------+------------------------------------------+
|name |description |locationUri |
+-------+---------------------+------------------------------------------+
|default|Default Hive database|hdfs://bdtest-001:8020/apps/hive/warehouse|
+-------+---------------------+------------------------------------------+
scala> spark.catalog.listTables.show(false)
+-------------------------+--------+----------------------------------------+---------+-----------+
|name |database|description |tableType|isTemporary|
+-------------------------+--------+----------------------------------------+---------+-----------+
|activity_donate_record |default |Imported by sqoop on 2018/01/08 19:03:33|MANAGED |false |
|activity_periods_config |default |Imported by sqoop on 2018/01/08 19:04:20|MANAGED |false |
|activity_result |default |Imported by sqoop on 2018/01/08 19:05:00|MANAGED |false |
|activity_school_info |default |Imported by sqoop on 2018/01/08 19:05:46|MANAGED |false |
|activity_season_game_data|default |Imported by sqoop on 2018/01/08 19:06:23|MANAGED |false |
|activity_season_game_log |default |Imported by sqoop on 2018/01/08 19:07:00|MANAGED |false |
|ana_tag |default |Imported by sqoop on 2018/01/08 19:07:35|MANAGED |false |
|ana_user_tag |default |Imported by sqoop on 2018/01/08 19:08:18|MANAGED |false |
|api_invoking_log |default |Imported by sqoop on 2018/01/08 19:08:58|MANAGED |false |
|app_function |default |Imported by sqoop on 2018/01/08 19:09:34|MANAGED |false |
|bank_card |default |Imported by sqoop on 2018/01/08 19:10:09|MANAGED |false |
|bank_card_bin |default |Imported by sqoop on 2018/01/08 19:10:46|MANAGED |false |
|command_invocation |default |Imported by sqoop on 2018/01/08 19:11:26|MANAGED |false |
|coupon_grant_log |default |Imported by sqoop on 2018/01/08 19:12:05|MANAGED |false |
|coupon_user |default |Imported by sqoop on 2018/01/08 19:12:43|MANAGED |false |
|device_command |default |Imported by sqoop on 2018/01/08 19:13:18|MANAGED |false |
|device_preorder |default |Imported by sqoop on 2018/01/08 19:13:54|MANAGED |false |
|dro_dropdetails |default |null |MANAGED |false |
|dro_dropinfo |default |Imported by sqoop on 2018/01/08 19:15:09|MANAGED |false |
|dro_exchange_record |default |Imported by sqoop on 2018/01/08 19:15:43|MANAGED |false |
+-------------------------+--------+----------------------------------------+---------+-----------+
only showing top 20 rows
DataFrame 和 Datasets
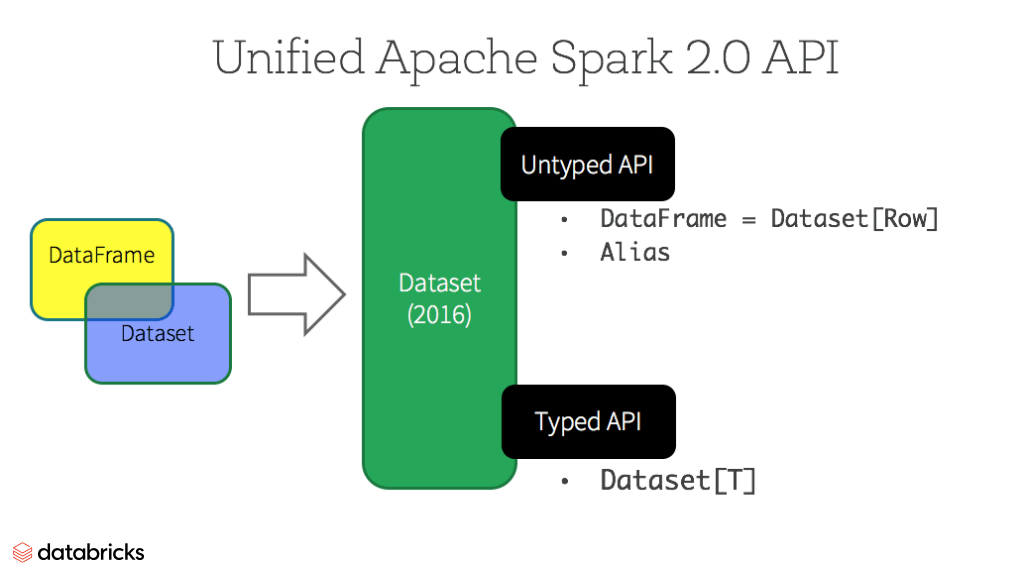
Dataset:
- 强类型
- 支持functional和relational操作
- 操作分类
- 转换(transformation):用于产生新的Datasets
- 例如:map,filter,select,aggregate(groupBy)
- 操作(actions):触发计算并返回结果
- 例如:count,show,把数据写回文件系统
- 转换(transformation):用于产生新的Datasets
- lazy:计算只有到action触发的时候才进行。Dataset内部可以理解为存储了如何进行计算的计划。当action执行的时候Spark query optimizer生成并优化计算方案后将其执行。
Encoder:把JVM中的类型T跟Spark SQL的数据表现形式进行转换的机制。(marshal/unmarshal?)
两种创建方法:
使用SparkSession的read()方法
val people = spark.read.parquet("...").as[Person] // Scala Datasetpeople = spark.read().parquet("...").as(Encoders.bean(Person.class)); // Java 对现有Dataset做转换(transformation)
val names = people.map(_.name) // in Scala; names is a Dataset[String] Datasetnames = people.map((Person p) -> p.name, Encoders.STRING));
Dataset操作也可以是untyped,通过:Dataset, Column, DataFrame的function等。
列操作
- 选择一列(抛弃其他列):select(“column”)
- 增加一列:withColumn(“newColumn”, Column)
- 修改一列: withColumn(“column”, Column)
- 删除一列: drop(“column”)
- 类型转换:
列高级操作:
- UDF:
DataFrame:
- Dataset的无类型view (untyped view),对应Dataset的Row
- DataFrame操作Functions
DataFrame是有名列(named columns)组成的数据集合,类似关系数据库中的表或者python/R中的pandas。
可以由多种数据源来构造DataFrame,比如Hive中的table,Spark的RDD(Resilient Distributed Datasets)。
TODO: Datasets
SparkSession有很多种方法创建DataFrame和Datasets。
| DataFrame | 描述 | |
|---|---|---|
| 创建API | SparkSession.createDataFrame | |
| 访问 | ||
| 其他 |
| Datasets | 描述 | |
|---|---|---|
| 创建API | ||
| 访问 | ||
| 其他 |
Row
- 创建Row
访问
generic访问,使用ordinal序列访问
row(0):访问列第一个成员
原始类型访问
Column
- DataSet API:
http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset
处理时间
* ver <= 1.5
使用hiveContext来查询
* 1.5 <= ver < 2.2
Spark 1.5引入了unix_timestamp(),所以在1.5之后到2.2的spark版本中可以这样操作时间信息
import org.apache.spark.sql.functions.{unix_timestamp, to_date}
val df = Seq((1L, "01-APR-2015")).toDF("id", "ts")
df.select(to_date(unix_timestamp(
$"ts", "dd-MMM-yyyy"
).cast("timestamp")).alias("timestamp"))
* ver >= 2.2
import org.apache.spark.sql.functions.{to_date, to_timestamp}
df.select(to_date($"ts", "dd-MMM-yyyy").alias("date"))
df.select(to_timestamp($"ts", "dd-MM-yyyy HH:mm:ss").alias("timestamp"))
import spark.implicits._
引入toDF()方法和“$”操作符
编程陷阱
陷阱1:dataframe有元素,但通过循环把值放入ListBuffer()后ListBuffer()却为空列表
val valueDF = allData.select("value").distinct()
valueDF.show()
//valueDF.foreach(r => valueList.append(r.getAs[Int]("value")))
for (row <- valueDF) {
println("value:" + row.getAs[Int]("value"))
valueList.append(row.getAs[Int]("value"))
}
println("Values:" + valueList)
valueList.foreach(println))
// 程序运行输出
+-------+
|value |
+-------+
| 1|
| 3|
| 5|
| 4|
| 10|
| 2|
| 0|
+-------+
Values:ListBuffer()
可以看出两个问题: * 问题1: 虽然可以知道valueDF不为空,可是”println(…)“却没有任何输出内容 * 问题2: 结果valueList为空
原因:
Spark任务执行是通过Driver/Executor来完成的,Driver控制任务执行,Executor负责任务执行,foreach/for会被Driver分配给Executor来执行(分布式执行),每个Executor创建一个自己的ListBuffer拷贝,因此当任务结束后信息就丢失了。
参考Stackoverflow的讨论:https://stackoverflow.com/questions/36203299/scala-listbuffer-emptying-itself-after-every-add-in-loop
修复方法:使用collect()
collect()定义:
def collect(): Array[T]
Returns an array that contains all rows in this Dataset.
Running collect requires moving all the data into the application’s driver
process, and doing so on a very large dataset can crash the driver process with
OutOfMemoryError.
For Java API, use collectAsList.
修复代码如下:
val valueDF = allData.select(“value”).distinct()
valueDF.show()
//valueDF.foreach(r => valueList.append(r.getAs[Int](“value”)))
for (row <- valueDF.collect()) {
println(“value:” + row.getAs[Int](“value”))
valueList.append(row.getAs[Int](“value”))
}
println(“getAllChannels:” + valueList)
// 程序运行输出如下
+——-+
|value |
+——-+
| 1|
| 3|
| 5|
| 4|
| 10|
| 2|
| 0|
+——-+
value:1
value:3
value:5
value:4
value:10
value:2
value:0
getAllChannels:ListBuffer(1, 3, 5, 4, 10, 2, 0)
