Sqoop介绍及使用
1. HDP中使用sqoop进行工作流处理准备工作
1.1 准备hdfs中的用户目录
在进行hdfs操作前需要切换用户到’hdfs’
# su - hdfs为操作用户创建hdfs环境
此处为ambari的admin用户准备环境:
$ hdfs dfs -mkdir /user/admin
$ hdfs dfs -chown admin:hdfs /user/admin
$ hdfs dfs -ls /user
$ hdfs dfs -chmod -R 770 /user/admin
1.2 配置ozzie
设置ozzie进程在hdfs中的proxy user
配置项:hadoop.proxyuser.oozie.groups 值:$USER_GROUPS_THAT_ALLOW_IMPERSONATION 配置项: hadoop.proxyuser.oozie.hosts 值:$OOZIE_SERVER_HOSTNAME
PS. 代理机制 :http://dongxicheng.org/mapreduce-nextgen/hadoop-secure-impersonation/

主备namenode和resoucemanager(hadoop 2.0)上的core-site.xml中增加以下配置:
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>group1,group2<value>
</property>
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>host1,host2<value>
</property>
这里,假设用户user1属于group1(注意,这里的user1和group1都是linux用户和用户组,需要在namenode和jobtracker上进行添加),此外,为了限制客户端随意部署,超级用户代理功能只支持host1和host2两个节点。经过以上配置后,在host1和host2上的客户端上,属于group1和group2的用户可以sudo成oozie用户,执行作业流。
- 拷贝mysql-connector及配置
切换到oozie用户后执行:
# 复制mysql-connector
$ hdfs dfs -put /$PATH/mysql-connector-java-5.1.37.jar /user/oozie/share/lib/lib_$TIMESTAMP/sqoop
# 复制配置文件
$ hdfs dfs -put /etc/hive/conf/hive-site.xml /user/oozie/share/lib/lib_20171226172323/hive
$ hdfs dfs -put /etc/hive2/conf/hive-site.xml /user/oozie/share/lib/lib_20171226172323/hive2
# 通知Ozzie使用新的sharelib
$ oozie admin -sharelibupdate
sqoop基本操作
https://sqoop.apache.org/docs/1.4.4/SqoopUserGuide.html#_importing_data_into_hive
列举数据库(list-databases)
# sqoop list-databases --connect jdbc:mysql://192.168.1.1/iot_test_12 --username iot -P SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/hdp/2.6.3.0-235/hadoop/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/hdp/2.6.3.0-235/accumulo/lib/slf4j-log4j12.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 17/12/25 18:27:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6.2.6.3.0-235 Enter password: 17/12/25 18:27:44 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. information_schema iot_test_12 mysql简单查询(eval)
# sqoop eval --connect jdbc:mysql://192.168.1.1/iot_test_12 --username iot -P --query "select date(add_time), count(*) from device group by date(add_time)" SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/hdp/2.6.3.0-235/hadoop/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/hdp/2.6.3.0-235/accumulo/lib/slf4j-log4j12.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 17/12/25 18:32:47 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6.2.6.3.0-235 Enter password: 17/12/25 18:32:52 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. ------------------------------------- | date(add_time) | count(*) | ------------------------------------- | 2017-06-16 | 3 | | 2017-06-23 | 1 | | 2017-06-28 | 1 | | 2017-07-06 | 1 | | 2017-07-15 | 1 | | 2017-07-24 | 6 | | 2017-07-25 | 2 | | 2017-07-26 | 11 | | 2017-07-27 | 56 | | 2017-07-28 | 2 | | 2017-07-29 | 28 | | 2017-07-31 | 373 | | 2017-08-01 | 96 | | 2017-08-02 | 3 | | 2017-08-03 | 2 | | 2017-08-09 | 2 | | 2017-08-15 | 1 | | 2017-08-19 | 1 | | 2017-09-02 | 4 | | 2017-09-07 | 4 | | 2017-09-08 | 1 | | 2017-09-19 | 3 | | 2017-10-10 | 1 | | 2017-11-02 | 2 | | 2017-11-03 | 1 | | 2017-11-17 | 1 | | 2017-11-29 | 1 | | 2017-12-04 | 2 | | 2017-12-05 | 1 | | 2017-12-07 | 1 | | 2017-12-15 | 1 | -------------------------------------导入hive
- 将一张表导入hive:
注意,需要使用hive用户:
# su - hive
$ sqoop-import --connect jdbc:mysql://192.168.1.1/iot_test_12 --username iot -P --table device --hive-import -m 1
导入后的数据可以从hdfs中看到:
$ hdfs dfs -ls /apps/hive/warehouse/device
Found 1 items
-rwxrwxrwx 3 hive hadoop 62177 2017-12-27 18:11 /apps/hive/warehouse/device/part-m-00000
配置hive-site.xml的warehouse:
<property>
<name>hive.warehouse.subdir.inherit.perms</name>
<value>true</value>
</property>
将所有表导入hive:
# su - hive $ sqoop import-all-tables --connect jdbc:mysql://192.168.1.1/iot_test_12 --username iot -P --warehouse-dir /apps/hive/warehouse/IOT --hive-import --create-hive-table -m 1指定目标目录(–warehouse-dir /apps/hive/warehouse/IOT):
从hive导出
$ sqoop export --connect jdbc:mysql://localhost/db --username root --table employee --export-dir /emp/emp_dataJob管理
sqoop job --list sqoop job --show 'jobname' sqoop job --exec 'jobname'
Issue 1:
Application is added to the scheduler and is not yet activated. Queue’s AM resource limit exceeded. Details :
AM Partition =
创建工作流(WFM)
1.创建动作用sqoop获取数据
Create the Sqoop Action to Extract Data
Command: import –connect jdbc:mysql://192.168.1.1/iot_test_12 –username iot –password-file /user/admin/iot.passwd –table iottest –split-by rowkey –hive-import -m 1
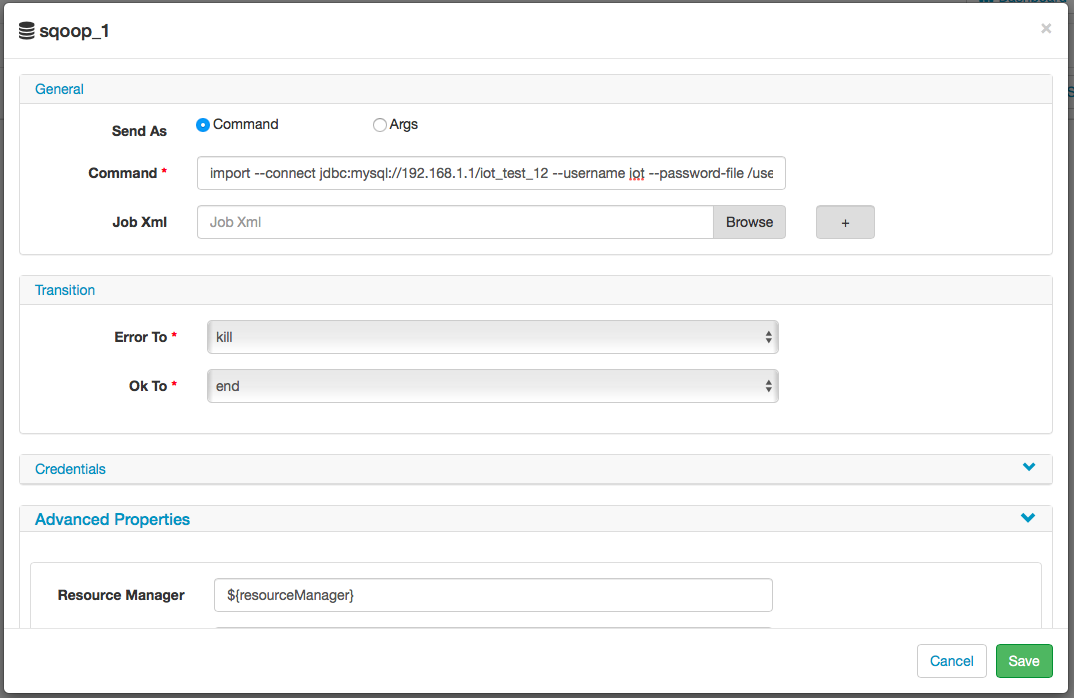
Advanced -> File:
/user/oozie/share/lib/lib_20171226172323/hive/hive-site.xml
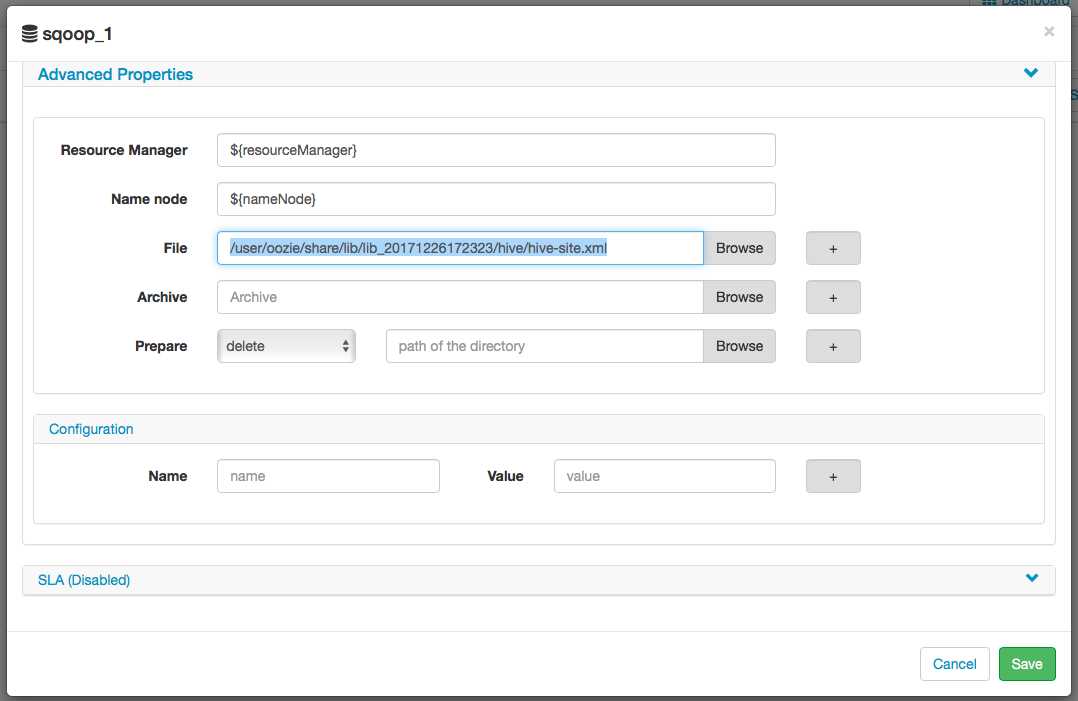
2.
Ambari restart
1) Shut down all services using Ambari.
2) Shutdown ambari-agents on all nodes.
3) Shutdown ambari-server.
4) Reboot all nodes as required .
5) Restart ambari-server, agents and services in that order.
hadoop
停止Hadoop任务:
hadoop job -kill job-id
misc
Apache Tez
The Apache TEZ® project is aimed at building an application framework which allows for a complex directed-acyclic-graph of tasks for processing data. It is currently built atop Apache Hadoop YARN.
Tez — (manage DAG task) —> Yarn
Empowering end users by:
- Expressive dataflow definition APIs
- Flexible Input-Processor-Output runtime model
- Data type agnostic
- Simplifying deployment
Execution Performance:
- Performance gains over Map Reduce
- Optimal resource management
- Plan reconfiguration at runtime
- Dynamic physical data flow decisions
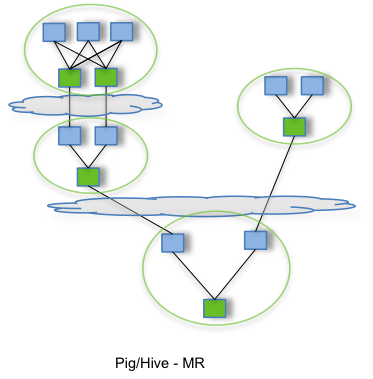
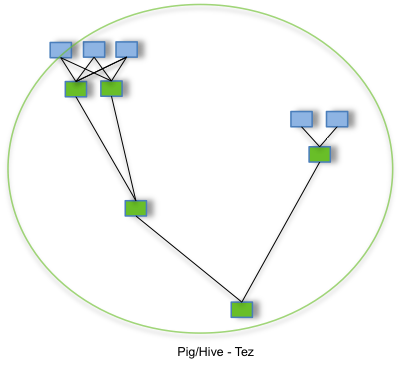
HDP中提交的Hive查询任务通过Tez调度执行
